Quality Explained and Predicted
When a considerable number of MTMM experiments is performed and the quality indicators of the questions are estimated, one can also try to explain where the differences in quality come from. This can come from different characteristics of the questions such as the topic, the basic concept measured, the formulation of the question, the response scale but also the data collection method etc. Andrews (1984) who was the first to do many MTMM experiments was also the first to do such a “meta analysis” to explain the quality of questions formulated in English and tested in the USA. A similar study has been reported by Rodgers, Andrews and Herzog (1992) based on a Michican (USA) panel study. After that followed similar studies in Austria (Költringer 1995), in the Netherlands (Scherpenzeel and Saris 1997).
Cross-national studies
After these country specific studies an effort was made to integrate data from different countries. First of all, life satisfaction questions collected in different European countries were studied (Saris and Van Wijk (1998). After that a more general code book was made to code the 1023 questions evaluated in 87 studies mentioned above in English (USA), in German (Austria), and in Dutch (the Netherlands and Belgium). The meta-analyses were done using regression analysis using as dependent variables the quality indicators reliability and validity (values between 0 and 1) estimates of all 1023 questions. The explanatory variables were the coded characteristics of the questions. The results have been reported in Saris and Gallhofer (2007). A typical example of this research was the result presented below with respect to different aspects of the formulation of the questions and the basic choice of the response scales.
After these country specific studies an effort was made to integrate data from different countries. First of all, life satisfaction questions collected in different European countries were studied (Saris and Van Wijk (1998). After that a more general code book was made to code the 1023 questions evaluated in 87 studies mentioned above in English (USA), in German (Austria), and in Dutch (the Netherlands and Belgium). The meta-analyses were done using regression analysis using as dependent variables the quality indicators reliability and validity (values between 0 and 1) estimates of all 1023 questions. The explanatory variables were the coded characteristics of the questions. The results have been reported in Saris and Gallhofer (2007). A typical example of this research was the result presented below with respect to different aspects of the formulation of the questions and the basic choice of the response scales.
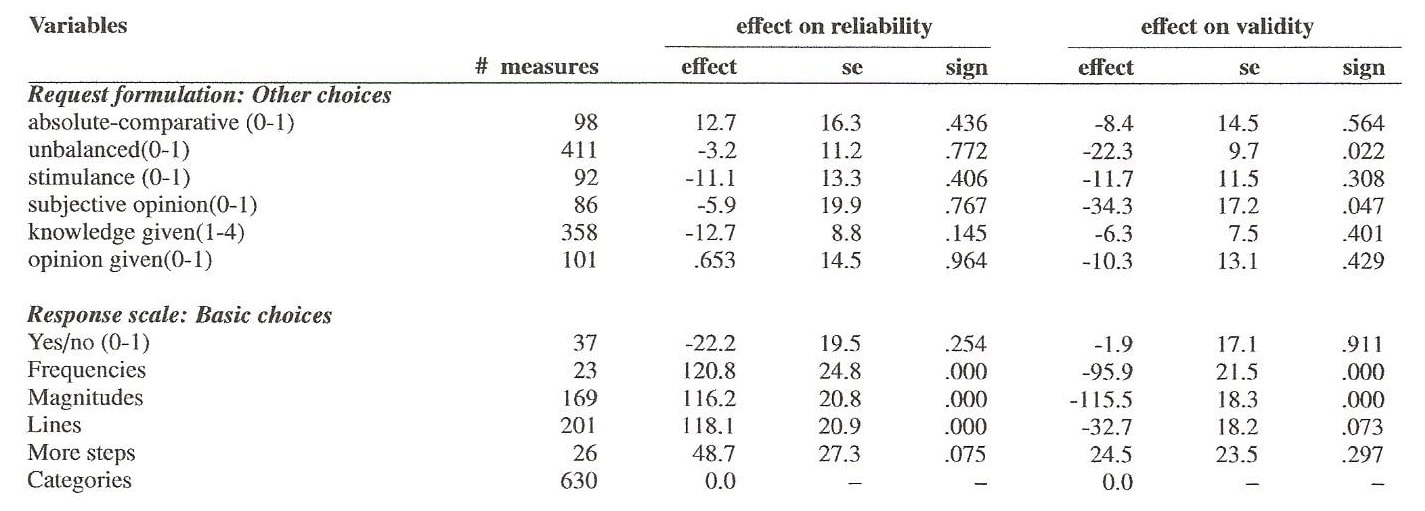
This table only presents a small part of the total result of the meta analysis. The table presents the regression coefficients multiplied by 1000 for the variables presented in the first column. The different aspects of the formulation of the request have hardly any significant effects on the reliability and validity. This is different for the variable response scale. This is a nominal variable and is therefore split up in several dummy variables with as reference variable the category scale which for that reason has an effect of zero. So the effects of the other response scales are expressed in comparison with the quality of the category scale. The response scales denoted as frequencies, magnitudes and lines have a significant better reliability, close to 0.12, than the category scale. The yes/no scale has less reliability than the category scale but this effect is not significant. In the same way the effects on the validity can be interpreted. The results show that the effects on the validity of a question can be quite different from the effect on the reliability. For all other results we refer to Saris and Gallhofer (2007).
The first programs to predict the quality of questions
The explained variances for the validity and reliability by the characteristics of the questions were rather high (.61 and .47). Therefore, the idea was born to use the derived regression equations also for prediction of the quality of new questions. The users would have to specify a question and code the question using the options specified in the meta analysis. Then the computer could predict the quality of the questions using the derived regresion coefficients and even suggest in what way the quality could be improved. This first program was called SQP.Dos, which stands for Survey Quality Prediction. Dos was added because it was developed for Dos (Saris 2001). Later this first prediction program was converted to Windows (SQP1.0) by Oberski, Kuipers and Saris (2005).
It will be clear that this was so far a nice exercise but one would like to have more questions evaluated in order to be able to study more interaction effects. One would also like to have data form more countries so that the predictions could be made for questions in more than three languages.
These wishes were satisfied when the researchers of the SRF got the opportunity to participate in the ESS and to include MTMM studies in European Social Survey (ESS).
The explained variances for the validity and reliability by the characteristics of the questions were rather high (.61 and .47). Therefore, the idea was born to use the derived regression equations also for prediction of the quality of new questions. The users would have to specify a question and code the question using the options specified in the meta analysis. Then the computer could predict the quality of the questions using the derived regresion coefficients and even suggest in what way the quality could be improved. This first program was called SQP.Dos, which stands for Survey Quality Prediction. Dos was added because it was developed for Dos (Saris 2001). Later this first prediction program was converted to Windows (SQP1.0) by Oberski, Kuipers and Saris (2005).
It will be clear that this was so far a nice exercise but one would like to have more questions evaluated in order to be able to study more interaction effects. One would also like to have data form more countries so that the predictions could be made for questions in more than three languages.
These wishes were satisfied when the researchers of the SRF got the opportunity to participate in the ESS and to include MTMM studies in European Social Survey (ESS).
Development of SQP2.0
The ESS started in 2001 and each two years a large survey was done in countries of Europe and other countries that were members of the European Science Foundation (Israel, Russia and Turkey) that were willing and could afford to participate. The number of countries varied from 16 in the beginning till over 30 in later rounds. Each country was obliged to collect the data using a translation of source questionnaire. The data were collected by personal interviews. The samples were expected to be random samples of the population of minimally 1500 respondents above 16 years.
In each round normally 5 experiments were done using the 2 group Spit Ballot MTMM design (see above). The experiments were based on questions that were asked in the main questionnaire. In order to realize the second measures of the same questions a supplementary questionnaire was added to the main questionnaire. In this supplementary questionnaire different random groups got different forms of the same questions that were asked in the main questionnaire.
In this way the MTMM experiments were performed and after 3 rounds we had in this way collected in each round 5 studies, in around 25 countries and so we got (3 x 5 x 25 x 9 questions =) 1861 questions in more than 20 languages. While we could add to this number 1023 questions from the older studies which brings the total number on 2884. We thought that this would be enough to try to create a new version of SQP based on this larger data set of questions in many more countries.
To take all possible interactions into account and obtain optimal predictability of the quality estimates a different procedure was used in the meta analysis. The used procedures, the Random Forest (Breiman ) is based on the creation of a large number of regression trees. An example of a single regression tree is given below. The tree in the Figure below gives a prediction of the logit of the reliability coefficient for a question with given characteristics. For example, suppose the question asked is: “Do you think the government does a good job?” with answers ranging from “the worst job” to “quite a good job”.
The ESS started in 2001 and each two years a large survey was done in countries of Europe and other countries that were members of the European Science Foundation (Israel, Russia and Turkey) that were willing and could afford to participate. The number of countries varied from 16 in the beginning till over 30 in later rounds. Each country was obliged to collect the data using a translation of source questionnaire. The data were collected by personal interviews. The samples were expected to be random samples of the population of minimally 1500 respondents above 16 years.
In each round normally 5 experiments were done using the 2 group Spit Ballot MTMM design (see above). The experiments were based on questions that were asked in the main questionnaire. In order to realize the second measures of the same questions a supplementary questionnaire was added to the main questionnaire. In this supplementary questionnaire different random groups got different forms of the same questions that were asked in the main questionnaire.
In this way the MTMM experiments were performed and after 3 rounds we had in this way collected in each round 5 studies, in around 25 countries and so we got (3 x 5 x 25 x 9 questions =) 1861 questions in more than 20 languages. While we could add to this number 1023 questions from the older studies which brings the total number on 2884. We thought that this would be enough to try to create a new version of SQP based on this larger data set of questions in many more countries.
To take all possible interactions into account and obtain optimal predictability of the quality estimates a different procedure was used in the meta analysis. The used procedures, the Random Forest (Breiman ) is based on the creation of a large number of regression trees. An example of a single regression tree is given below. The tree in the Figure below gives a prediction of the logit of the reliability coefficient for a question with given characteristics. For example, suppose the question asked is: “Do you think the government does a good job?” with answers ranging from “the worst job” to “quite a good job”.
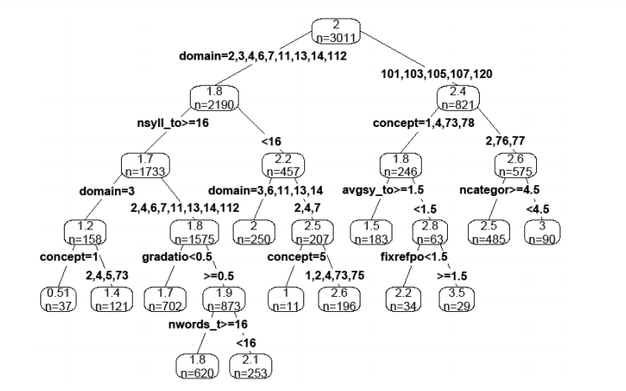
The top node splits off depending on the domain, in this case national government (domain=101). Afterwards we follow the split on concept to the left-hand node, because the question asks an “evaluative belief” (concept= 1). The average number of syllables per word is then the next relevant variable, which in this case is 1.22; less than 1.5. Finally, there is only one fixed reference point, so that the prediction of the logit value ends up being 2.2. This prediction was based on 34 observations. This logit value can be transformed in a value of a reliability coefficient by taking the inverse of this value or invlogit(2.2) = 0.90. So according to this tree the reliability would be predicted to be 0.90.
The tree given above is only given as an example output of the CART procedure, and does not necessarily corresponds to any tree used in the final prediction. In fact 1500 of these trees are created and the overall prediction is then taken as an average over all 1500 trees in the “forest”. Given the amount of information available in all these trees a distribution of the predictions is obtained and this information can be used to determine the means and specify prediction intervals and standard deviations which are then presents as the prediction for a specific question with these specific characteristics. For more details of this procedure we refer to Oberski, Thomas and Saris (2011) and Saris and Gallhofer (2014)
It will be clear that this approach is very different from the meta-analysis using regression analysis. In the Random forest procedure the emphasis is on the optimal prediction of the reliability and validity while in the regression procedure the emphasis is on determining the effect of the different characteristics on the quality indicators. The random Forest procedure does not provide such information.
SQP2.1 has been developed mainly for the prediction of the quality of the questions and for suggestions to improve the quality of the questions. In the next section this program has been presented.
The tree given above is only given as an example output of the CART procedure, and does not necessarily corresponds to any tree used in the final prediction. In fact 1500 of these trees are created and the overall prediction is then taken as an average over all 1500 trees in the “forest”. Given the amount of information available in all these trees a distribution of the predictions is obtained and this information can be used to determine the means and specify prediction intervals and standard deviations which are then presents as the prediction for a specific question with these specific characteristics. For more details of this procedure we refer to Oberski, Thomas and Saris (2011) and Saris and Gallhofer (2014)
It will be clear that this approach is very different from the meta-analysis using regression analysis. In the Random forest procedure the emphasis is on the optimal prediction of the reliability and validity while in the regression procedure the emphasis is on determining the effect of the different characteristics on the quality indicators. The random Forest procedure does not provide such information.
SQP2.1 has been developed mainly for the prediction of the quality of the questions and for suggestions to improve the quality of the questions. In the next section this program has been presented.
References:
Breiman L. (2001) Random Forests. Machine learning. 45, 5-32
Oberski D, T Gruner and W. Saris (2011) The prediction procedure the quality of the questions based on the present data base of questions In Saris W. , D. Oberski, M. Revilla, D. Zavala, L. Lilleoja, I.Gallhofer and T. Gruner (2011) The development of the program SQP 2.0 for the prediction of the quality of survey questions, RECSM Working paper 24 (chapter 6)
Saris W.E. and I.N.Gallhofer (2007) Design, evaluation and analysis of questionnaires for survey research. Hoboken, Wiley, (chapter 12)
Saris W.E. and I.N.Gallhofer (2014) Design, evaluation and analysis of questionnaires for survey research. Hoboken, Wiley, (chapter 9 and 10)
Breiman L. (2001) Random Forests. Machine learning. 45, 5-32
Oberski D, T Gruner and W. Saris (2011) The prediction procedure the quality of the questions based on the present data base of questions In Saris W. , D. Oberski, M. Revilla, D. Zavala, L. Lilleoja, I.Gallhofer and T. Gruner (2011) The development of the program SQP 2.0 for the prediction of the quality of survey questions, RECSM Working paper 24 (chapter 6)
Saris W.E. and I.N.Gallhofer (2007) Design, evaluation and analysis of questionnaires for survey research. Hoboken, Wiley, (chapter 12)
Saris W.E. and I.N.Gallhofer (2014) Design, evaluation and analysis of questionnaires for survey research. Hoboken, Wiley, (chapter 9 and 10)
